Big-O ?
- 알고리즘의 성능을 수학적으로 표현해주는 기법
- 알고리즘의 시간과 공간복잡도를 표현
- Big-O 표기법은 알고리즘의 실제 러닝타임을 표기하는 것이라기보단, 데이터나 사용자의 증가율에 따른 알고리즘 성능을 예측하는게 목표이기 때문에 상수와 같은 숫자들은 모두 1이 된다.
O(1) : constant time
입력데이터 크기와 상관없이 언제나 일정한 시간이 걸리는 알고리즘의 시간복잡도

F(int[] n) {
return (n[0] == 0) ? true : false;
}
n의 크기가 1개이던 100,000개이던 상관없이 언제나 일정한 속도로 결과를 반환하는 이런 알고리즘을 'O(1)의 시간복잡도를 가진다' 라고 표현한다.
O(n) : linear time
입력데이터 크기에 비례해 처리시간이 걸리는 알고리즘의 시간복잡도

F(int[] n) {
for i = 0 to n.length
print i
}
n 개의 데이터를 받으면 n번 loop를 돌기 때문에, n의 크기가 늘어나면 그만큼 비례해서 처리 속도가 늘어난다.
데이터가 증가함에 따라 비례해서 처리시간도 증가한다.
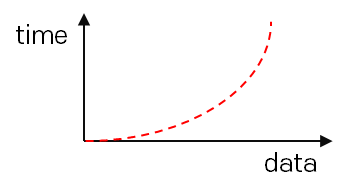
O(n²) : quadratic time
n개의 입력데이터가 각각 n번씩 스텝을 밟아 데이터가 커질수록 처리시간이 커지는 알고리즘의 시간복잡도
F(int[] n) {
for i = 0 to n.length
for j = 0 to n.length
print i + j;
}
O(nm) : quadratic time
O(n²)과 비슷함, n을 n만큼 돌리는게 아닌 n을 m만큼 돌리는 것
F(int[] n, int[] m) {
for i = 0 to n.length
for j = 0 to m.length
print i + j;
}
O(n³) : polynomail / cubic time

F(int[] n) {
for i = 0 to n.length
for j = 0 to n.length
for k = 0 to n.length
print i + j + k;
}
O(2ⁿ) : exponential time

Fibonacci 수열
한 면을 기준으로 정사각형을 만들어나가는 피보나치 수열을 재귀함수를 이용한 코드이다.
F(n, r) {
if (n <= 0) return 0;
else if (n == 1) return r[n] = 1;
return r[n] = F(n - 1, r) + F(n - 2, r);
}


O(mⁿ) : exponential time
m개씩 n번 늘어나는 알고리즘의 시간복잡도
O(logn)
대표 알고리즘인 이진검색(binary search) 의 시간복잡도로, 한 번 단계를 거칠 때마다 처리시간이 절반씩 줄어드는 알고리즘의 시간복잡도

F(k, arr, s, e) {
if(s > e) return -1;
m = (s + e) / 2;
if(arr[m] == k) return m;
else if(arr[m] > k) return F(k, arr, s, m-1);
else reutrn F(k,arr,m+1,e);
}
O(sqrt(n))
* 제곱근(squareroot) : √100 → 10
입력데이터 n = 16 이면, sqrt(n) = 4
Big-O 표기법의 중요한 특징
Drop Constants : 상수는 버린다
앞에서 말한바와 같이, Big-O는 실제 알고리즘 러닝타임을 재기 위해 만든 것이 아닌, 장기적으로 데이터가 증가함에 따른 처리시간의 증가율을 예측하기 위해 만든 표기법이기에 상수는 무시한다.
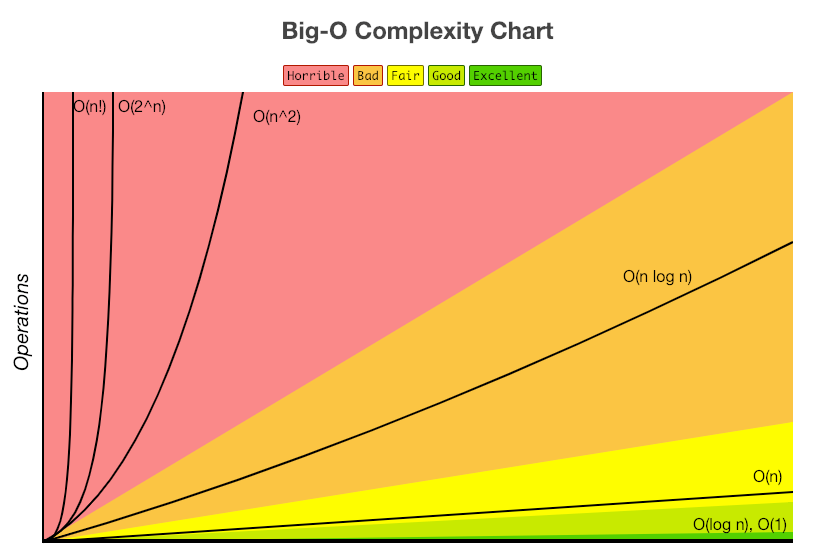
출처 : Big-O Algorithm Complexity Cheat Sheet (Know Thy Complexities!)

댓글